

🔧 ۱. مبانی هوش مصنوعی و یادگیری ماشین
تفاوت هوش مصنوعی (AI)، یادگیری ماشین (ML) و یادگیری عمیق (DL)
انواع یادگیری: نظارتشده (Supervised)، بدون نظارت (Unsupervised)، تقویتی (Reinforcement Learning)
مراحل یک پروژه ML: جمعآوری داده، پاکسازی، انتخاب ویژگیها، آموزش مدل، ارزیابی و پیادهسازی
۱. تعریف مفاهیم کلیدی
🔹 هوش مصنوعی (AI – Artificial Intelligence)
شاخهای از علوم کامپیوتر است که هدف آن ساخت سیستمهایی است که مانند انسان فکر کنند، تصمیم بگیرند یا یاد بگیرند. از سیستم خبره گرفته تا رباتهای خودران و دستیارهای صوتی مثل Siri یا ChatGPT.
🔹 یادگیری ماشین (Machine Learning – ML)
زیرمجموعهای از AI است که به ماشینها بدون برنامهنویسی مستقیم یاد میدهد که از دادهها یاد بگیرند و الگوها را کشف کنند.
🔹 یادگیری عمیق (Deep Learning – DL)
زیرمجموعهای از ML که از شبکههای عصبی با لایههای زیاد استفاده میکند. مخصوصاً برای دادههای پیچیده مثل تصاویر، صدا، و دادههای سری زمانی طولانی.
۲. انواع یادگیری در ML
🔸 ۲.۱ یادگیری نظارتشده (Supervised Learning)
در این روش، ورودی و خروجی مشخص هستند. مدل با استفاده از دادههای برچسبدار آموزش میبیند.
مثالها:
پیشبینی زمان خرابی تجهیز (RUL Prediction)
تشخیص سالم یا معیوب بودن تجهیز
الگوریتمهای رایج:
Linear Regression
Decision Tree, Random Forest
SVM, XGBoost, Neural Networks
🔸 ۲.۲ یادگیری بدون نظارت (Unsupervised Learning)
فقط ورودی داریم و خروجی مشخص نیست. مدل باید ساختار داده را خودش کشف کند.
کاربرد در تشخیص ناهنجاری (Anomaly Detection)
خوشهبندی (Clustering)
الگوریتمهای رایج:
K-Means
DBSCAN
Autoencoders
🔸 ۲.۳ یادگیری تقویتی (Reinforcement Learning)
مدل با تعامل با محیط یاد میگیرد و از پاداش و جریمه برای بهبود تصمیمگیری استفاده میکند.
کاربرد صنعتی: بهینهسازی عملیات حفاری، کنترل مصرف انرژی
۳. مراحل کلی یک پروژه یادگیری ماشین
📌 ۱. تعریف مسئله
مثلاً: “پیشبینی خرابی کمپرسور حفاری با ۷۲ ساعت هشدار قبلی”
📌 ۲. جمعآوری داده
دادههای سنسور (ویبره، دما، صدا)
لاگهای عملیاتی، تاریخچه تعمیرات
📌 ۳. پاکسازی و آمادهسازی داده (Data Preprocessing)
حذف دادههای ناقص
نرمالسازی و استانداردسازی
استخراج ویژگیهای مهم (Feature Engineering)
📌 ۴. انتخاب مدل و آموزش (Model Training)
انتخاب الگوریتم مناسب
آموزش مدل با دادههای آموزشی
تنظیم پارامترها (Hyperparameter Tuning)
📌 ۵. ارزیابی مدل (Model Evaluation)
معیارهای ارزیابی:
دقت (Accuracy)
حساسیت (Recall)
AUC-ROC
MSE (برای رگرسیون)
📌 ۶. پیادهسازی مدل در سیستم واقعی
در Edge یا Cloud
اتصال به داشبورد مانیتورینگ
هشدار و اعلان
۴. الگوریتمهای پرکاربرد در حوزههای صنعتی
| نوع الگوریتم | کاربرد | مزیتها |
|---|---|---|
| Random Forest | طبقهبندی سالم/معیوب | دقت بالا، مقاوم در برابر نویز |
| XGBoost | پیشبینی خرابی | سرعت و دقت بالا |
| LSTM | سری زمانی مثل لرزش یا صدا | حفظ اطلاعات تاریخی |
| Autoencoder | تشخیص ناهنجاری | بدون نیاز به برچسب معیوب |
| One-Class SVM | تشخیص رفتار غیرنرمال | مناسب برای دادههای ناسالم |
۵. ملاحظات پیادهسازی در صنعت
⚙️ عملکرد در شرایط محیطی سخت (دما، گرد و غبار)
🕒 محدودیت زمان پاسخ و پیشبینی سریع
☁️ ارتباط بین Edge و Cloud
🔐 امنیت دادهها
📉 مقیاسپذیری و نگهداری
۶. مثال کاربردی در دکل حفاری
فرض کن یک سنسور ارتعاش روی موتور اصلی حفاری نصب شده.
از دادههای ۶ ماه گذشته استفاده میکنی تا مدل یاد بگیرد چه الگوهایی پیش از خرابی اتفاق افتادهاند.
مدل LSTM آموزش میبیند و در صورت مشاهده الگوهای مشابه، هشدار «احتمال خرابی در ۴۸ ساعت آینده» میدهد.
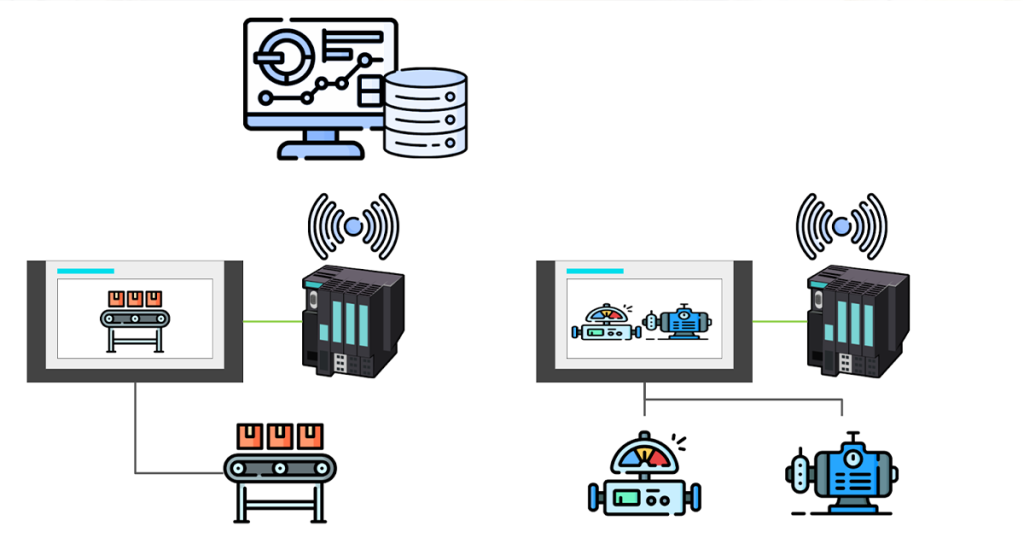
📊 ۲. پردازش سیگنال و دادههای صنعتی (Time Series)
دادههای سنسور (ویبره، صدا، فشار، دما، گشتاور و…)
تحلیل سریهای زمانی (Time-Series Analysis)
ویژگیهایی مثل روند (trend)، نوسان (seasonality)، نقطه تغییر (change points)
در صنایع سنگین مانند دکلهای حفاری چاه نفت، حجم زیادی از دادهها بهصورت پیوسته و وابسته به زمان از سنسورها دریافت میشود:
صدا، لرزش (Vibration)، دما، فشار، جریان، ولتاژ، موقعیت، گشتاور، و…
این نوع دادهها را سری زمانی (Time Series) مینامند.
🔹 ۲.۱ تعریف سری زمانی
سری زمانی مجموعهای از مشاهدات عددی است که در بازههای زمانی منظم ثبت میشود.
مثال:
دادهی لرزش یک موتور با نمونهبرداری هر 10 میلیثانیه
| زمان | شدت لرزش (g) |
|---|---|
| 10:00:00.000 | 0.12 |
| 10:00:00.010 | 0.13 |
| 10:00:00.020 | 0.14 |
🔹 ۲.۲ ویژگیهای خاص سری زمانی صنعتی
| ویژگی | توضیح |
|---|---|
| وابستگی زمانی (Temporal Dependency) | مقدار فعلی به مقادیر قبلی وابسته است |
| نویز زیاد | سنسورها معمولاً نویز دارند و دادهها نیاز به فیلتر دارند |
| رخدادهای نادر (Rare Events) | خرابیها کمتعداد اما بحرانیاند |
| نقطه تغییر (Change Point) | تغییر ناگهانی در رفتار تجهیز قبل از خرابی |
🔹 ۲.۳ مراحل پردازش سیگنال و سری زمانی
۱. جمعآوری داده (Data Acquisition)
با فرکانس بالا (مثلاً 1 کیلوهرتز)
با Timestamp دقیق
از سنسورهایی مانند:
Accelerometer
Microphone
Thermocouple
۲. پیشپردازش (Preprocessing)
حذف دادههای خراب یا پرت (Outliers)
نرمالسازی یا استانداردسازی
درونیابی (Interpolation) برای دادههای گمشده
فیلترکردن سیگنال (مثلاً با فیلتر Butterworth یا Kalman) برای کاهش نویز
۳. استخراج ویژگیها (Feature Extraction)
از هر پنجره زمانی (مثلاً 2 ثانیه)، ویژگیهای عددی استخراج میشود:
ویژگیهای زمانی (Time Domain):
میانگین، انحراف معیار
بیشینه، کمینه
RMS (ریشه میانگین مربعات)
skewness, kurtosis
ویژگیهای فرکانسی (Frequency Domain):
FFT (Fast Fourier Transform) برای استخراج فرکانس غالب
توان در باندهای مختلف فرکانسی
Spectrogram یا Wavelet Transform
ویژگیهای آماری:
انرژی سیگنال
نسبت قله به متوسط (Crest Factor)
Envelope Analysis
🎯 این ویژگیها ورودی مدل یادگیری ماشین میشوند.
۴. تحلیل سریهای زمانی
برای مدلسازی رفتار تجهیز از روشهای زیر استفاده میشود:
| روش | کاربرد |
|---|---|
| ARIMA / SARIMA | پیشبینی سریهای زمانی تکمتغیره |
| LSTM / GRU | مدلسازی وابستگی بلندمدت در دادههای پیچیده |
| CNN + LSTM | تحلیل سیگنالهای چندکاناله مانند صدا یا لرزش |
🔹 ۲.۴ شناسایی ناهنجاری (Anomaly Detection)
هدف: تشخیص تغییرات رفتاری که میتواند نشانه خرابی قریبالوقوع باشد.
روشهای پرکاربرد:
Autoencoder → مدل میآموزد رفتار نرمال چیست و خطا را بررسی میکند.
Isolation Forest → ناهنجاریها را از روی ویژگیهای آماری شناسایی میکند.
One-Class SVM → فقط با داده نرمال آموزش میبیند.
🔹 ۲.۵ تشخیص نقاط تغییر (Change Point Detection)
مهمترین نشانه آغاز خرابیها
الگوریتمهای ساده مثل: CUSUM، Bayesian Change Point
یا استفاده از شبکههای عصبی برای کشف رفتارهای جدید
🔹 ۲.۶ ابزارهای مفید برای پردازش سری زمانی
| ابزار | کاربرد | زبان |
|---|---|---|
| Python (Pandas, Numpy, Scipy) | تحلیل سری زمانی | پایتون |
| tsfresh | استخراج ویژگی خودکار | پایتون |
| PyWavelets | تحلیل wavelet سیگنالها | پایتون |
| MATLAB | فیلتر، FFT، مدلسازی | MATLAB |
| TensorFlow/Keras | آموزش LSTM و Autoencoder | پایتون |
🔹 ۲.۷ چالشهای رایج
کیفیت پایین داده (Missing, Noisy)
دادههای ناکافی از خرابی واقعی
نیاز به لیبلگذاری تخصصی (کارشناس فنی)
محاسبات سنگین برای تحلیل دادهها در Edge
🎯 نتیجه عملی
در پروژه شما، مثلاً برای دکل حفاری:
میتوان دادهی ویبره و صدا از پمپها و کمپرسورها را تحلیل کرد
با استفاده از FFT و LSTM رفتار نرمال استخراج میشود
در صورت مشاهده تغییرات در الگوی فرکانسی یا RMS، هشدار صادر میشود
🧠 ۳. الگوریتمهای یادگیری ماشین برای پیشبینی خرابیها
درخت تصمیم، Random Forest
XGBoost و LightGBM
شبکههای عصبی بازگشتی (RNN) و LSTM مخصوص سریهای زمانی
Autoencoder برای تشخیص ناهنجاری (Anomaly Detection)
Isolation Forest و One-Class SVM برای دادههای ناسالم
در سیستمهای صنعتی، هدف الگوریتمهای یادگیری ماشین، تشخیص و پیشبینی خرابیها قبل از وقوع آنهاست. این باعث کاهش توقفهای ناگهانی، صرفهجویی در هزینه و افزایش بهرهوری میشود.
📌 سه رویکرد اصلی در پیشبینی خرابی
| نوع | توضیح | مثال |
|---|---|---|
| تشخیص ناهنجاری (Anomaly Detection) | یافتن رفتار غیرمعمول | افزایش ناگهانی لرزش |
| طبقهبندی (Classification) | تشخیص سالم یا معیوب بودن سیستم | برچسب: “Normal” یا “Faulty” |
| پیشبینی عددی (Regression / RUL Estimation) | پیشبینی زمان باقیمانده تا خرابی (RUL) | «۳۵ ساعت تا خرابی» |
🧠 الگوریتمهای پرکاربرد برای پیشبینی خرابیها
۱. مدلهای ساده و قابل تفسیر (Baseline Models)
✅ Logistic Regression
مدل خطی برای طبقهبندی سالم / معیوب
ساده، سریع و قابل فهم
مناسب برای شروع پروژه با دادههای محدود
✅ Decision Tree / Random Forest
یادگیری بر اساس مجموعهای از قوانین
Random Forest بسیار قوی و مقاوم در برابر نویز
قابلیت شناسایی مهمترین ویژگیها
✅ Gradient Boosting (XGBoost, LightGBM, CatBoost)
دقت بالا در دادههای واقعی
یکی از بهترین انتخابها برای پیشبینی خرابی
مقاوم در برابر دادههای ناقص و پرت
۲. مدلهای مخصوص سریهای زمانی (Time Series Models)
✅ ARIMA / SARIMA
مدل آماری برای پیشبینی متغیرهای زمانی
ساده ولی محدود برای دادههای پیچیده
مناسب برای سریهای تکمتغیره مثل دمای یاتاقان
✅ LSTM (Long Short-Term Memory)
شبکه عصبی مناسب برای دادههایی با وابستگی زمانی بلندمدت
بسیار مناسب برای دادههای لرزش، صدا و پارامترهای تجهیزات
توانایی شناسایی روندهای پیش از خرابی
✅ GRU (Gated Recurrent Unit)
مشابه LSTM ولی سبکتر و سریعتر
مناسب برای کاربردهای Edge یا محدود به منابع
۳. مدلهای تشخیص ناهنجاری بدون نیاز به برچسب خرابی
✅ Autoencoder
شبکهای که ورودی را بازسازی میکند
خطای بازسازی بالا نشاندهنده رفتار غیرعادی است
بسیار مفید در سیستمهایی که داده سالم زیاد است اما داده خرابی کم
✅ Isolation Forest
الگوریتم جنگل تصادفی برای ناهنجاری
دادههای ناهنجار سریعتر ایزوله میشوند
✅ One-Class SVM
فقط با داده نرمال آموزش میبیند
هر دادهای که شبیه رفتار نرمال نباشد، ناهنجار محسوب میشود
🧪 مقایسه کلی الگوریتمها
| الگوریتم | مزیت | نقطه ضعف | کاربرد توصیهشده |
|---|---|---|---|
| Random Forest | ساده، قابل تفسیر | بهینهسازی سختتر | تشخیص سالم/معیوب |
| XGBoost | دقت بالا | نیاز به تنظیم زیاد | طبقهبندی و RUL |
| LSTM | درک توالی زمانی | نیاز به داده زیاد | داده لرزش/صدا |
| Autoencoder | بدون برچسب خرابی | پیچیدهتر | تشخیص ناهنجاری |
| One-Class SVM | فقط داده سالم نیاز دارد | مقیاسپذیری ضعیف | سیستمهای کمخرابی |
🛠 مثال عملی (برای دکل حفاری)
فرض کنید از موتور کمپرسور دادهی لرزش جمعآوری کردهاید:
استخراج ویژگیها از سیگنال:
RMS، فرکانس غالب، skewness و…
مدل Random Forest یا XGBoost آموزش میدهید:
برچسب دادهها: «خراب» یا «سالم» (در زمان یا پنجره زمانی خاص)
اگر دادههای خرابی ندارید:
از Autoencoder یا One-Class SVM برای شناسایی رفتارهای نرمال استفاده میکنید
🎯 نکات کلیدی در انتخاب الگوریتم
| معیار | توضیح |
|---|---|
| نوع داده | سری زمانی؟ چندکاناله؟ فرکانسی؟ |
| وجود برچسب خرابی | دارید یا ندارید؟ |
| محدودیت منابع محاسباتی | اجرا روی Edge یا Cloud؟ |
| قابل تفسیر بودن مدل | در صنعت مهم است، مهندسان باید مدل را بفهمند |
| میزان داده موجود | داده زیاد؟ داده نادر از خرابی؟ |
📍 مراحل پیشنهادی برای پروژه صنعتی واقعی:
جمعآوری و پاکسازی دادهها
مهندسی ویژگیها (تبدیل سیگنال به ویژگیهای عددی)
انتخاب الگوریتم مناسب:
Random Forest یا XGBoost (اگر داده خرابی دارید)
Autoencoder یا One-Class SVM (اگر داده فقط نرمال دارید)
LSTM (اگر وابستگی زمانی و داده بلندمدت دارید)
ارزیابی مدلها با داده تست
استقرار روی سیستم واقعی (Edge/Cloud)
مانیتور کردن خروجی مدل و بهروزرسانی آن با دادههای جدید

🧩 ۴. تحلیل رفتاری و تشخیص الگوی عملکرد تجهیزات
تعریف پروفایل نرمال رفتار تجهیز
تشخیص انحراف از رفتار نرمال
تحلیل Root Cause با استفاده از الگوهای داده
📌 تعریف کلی
تحلیل رفتاری (Behavioral Analysis) یعنی شناخت و مدلسازی الگوی نرمال عملکرد یک تجهیز صنعتی.
تشخیص الگو (Pattern Recognition) یعنی کشف الگوهای تکرارشونده، ناهنجاریها یا تغییرات تدریجی که ممکن است نشانه خرابی قریبالوقوع باشند.
✅ اهداف اصلی تحلیل رفتاری
| هدف | توضیح |
|---|---|
| مدلسازی عملکرد نرمال | ساخت مدل دقیق از رفتار نرمال در شرایط مختلف بار، دما، فشار و… |
| شناسایی ناهنجاریها (Anomalies) | کشف رفتارهایی که از حالت نرمال فاصله دارند |
| پیشبینی روند خرابی | شناسایی تغییرات تدریجی یا ناگهانی قبل از بروز خرابی |
| بصریسازی روندها | نمایش رفتار سیستم در گذر زمان برای تصمیمگیری بهتر |
🔍 انواع دادههای رفتاری از تجهیزات
| نوع داده | مثال | کاربرد |
|---|---|---|
| زمانی (Time Series) | دما، لرزش، فشار | تحلیل روند و نوسانات |
| فرکانسی (FFT) | طیف لرزش موتور | تشخیص خطای بلبرینگ |
| رویدادی (Event-Based) | روشن/خاموش شدن کمپرسور | تحلیل توالی رفتار |
| تصویری / صوتی | صدای غیرعادی موتور | تشخیص خطای مکانیکی با AI |
🧰 روشهای تحلیل رفتاری
۱. تحلیل آماری کلاسیک
میانگین، واریانس، انحراف معیار، چولگی، کشیدگی
تشخیص تغییرات در این مقادیر به عنوان نشانه خرابی
ساده اما محدود
۲. تحلیل فرکانسی (FFT, STFT, Wavelet)
تبدیل داده زمانی به حوزه فرکانس
کاربردی در سیستمهای چرخشی (موتور، بلبرینگ، پمپ)
تشخیص ترک یا عدم بالانس
۳. تحلیل یادگیری ماشین / هوش مصنوعی
ساخت مدل از دادههای نرمال
تشخیص الگوهای رفتاری با:
Autoencoder
Isolation Forest
LSTM/GRU
کشف الگوهای پنهان که با روشهای آماری قابل مشاهده نیستند
🔄 رویکردهای تشخیص الگو
✅ Pattern Matching / Template Matching
تطبیق رفتار فعلی با الگوی ثبتشده قبلی
مثل تشخیص اثر انگشت رفتاری
✅ Clustering (خوشهبندی)
بدون برچسب: دستهبندی رفتارهای مشابه
الگوریتمها: K-Means، DBSCAN، SOM
تشخیص حالتهای مختلف کارکرد دستگاه
✅ Sequence Modeling (مدلسازی توالیها)
تحلیل رفتار به صورت زنجیرهای
استفاده از LSTM و GRU برای یادگیری ترتیب و الگوهای زمانی
مناسب برای سیستمهایی با تغییرات تدریجی (مثل فرسایش)
🧪 مثال کاربردی در صنعت نفت (دکل حفاری)
🎯 داده:
لرزش پمپ گل حفاری در بازه زمانی ۱ ماه
دما، فشار، توان مصرفی
🎯 تحلیل:
محاسبه شاخص RMS، Kurtosis، Skewness از لرزش
رسم گراف روند تغییرات در زمان
استفاده از Clustering برای دستهبندی حالات کاری (سالم، خسته، بحرانی)
آموزش Autoencoder برای بازسازی رفتار نرمال → هر خطای بازسازی بزرگ → نشانه ناهنجاری
مدل LSTM برای پیشبینی داده آینده و شناسایی انحراف از الگوی نرمال
📊 خروجیهای مفید برای اپراتورها و مهندسان
| ابزار | کاربرد |
|---|---|
| داشبورد رفتار نرمال | نمایش محدودههای قابل قبول برای هر سنسور |
| سیستم هشدار (Alarm) | زمانی که رفتار از محدوده خارج شود |
| نقشه حرارتی الگوها (Heatmap) | تحلیل روندها در کل سیستم |
| نمودارهای RUL / Trend | زمان تخمینی باقیمانده تا خرابی |
⚠️ چالشها در تحلیل رفتاری
| چالش | توضیح |
|---|---|
| داده ناقص یا نویزی | سنسورها ممکن است قطع شوند یا داده اشتباه دهند |
| شرایط کاری متغیر | تغییر بار یا دما ممکن است رفتار را تغییر دهد بدون خرابی |
| تجهیزات مشابه با رفتار متفاوت | باید برای هر تجهیز مدل اختصاصی یا تطبیقی ساخت |
| کمبود داده خرابی | در صورت نبودن داده خرابی، باید از روشهای بدون نظارت استفاده شود |
✅ نتیجهگیری
تحلیل رفتاری یعنی فهم عمیق از رفتار واقعی سیستم، که با ترکیب دانش صنعتی و الگوریتمهای هوش مصنوعی میتواند به پیشبینی دقیقتر خرابیها و تصمیمگیری هوشمندانه در نگهداری کمک کند.
🔍 ۵. نگهداری پیشگویانه (Predictive Maintenance)
تفاوت با نگهداری پیشگیرانه
KPIهای کلیدی: MTBF، MTTR، RUL (Remaining Useful Life)
فریمورکهایی مثل PHM (Prognostics and Health Management)
✅ تعریف
نگهداری پیشگویانه یعنی پیشبینی زمان خرابی یا کاهش عملکرد یک تجهیز قبل از وقوع واقعی آن، با استفاده از دادههای واقعی از عملکرد دستگاه (مثل دما، لرزش، صدا، جریان و غیره) و تحلیل آنها با الگوریتمهای پیشرفته.
🎯 هدف PdM
| هدف | توضیح |
|---|---|
| جلوگیری از خرابی ناگهانی | با پیشبینی زمان خرابی، میتوان برنامهریزی کرد و از توقف تولید جلوگیری کرد |
| افزایش عمر تجهیزات | با مداخله بهموقع، از فرسایش شدید و تخریب جلوگیری میشود |
| کاهش هزینههای نگهداری | فقط زمانی که لازم است، تعمیر انجام میشود (نه زودتر، نه دیرتر) |
| افزایش بهرهوری و ایمنی | کاهش ریسک، افزایش زمان کارکرد و کاهش حوادث صنعتی |
📊 تفاوت با روشهای دیگر نگهداری
| نوع نگهداری | زمان مداخله | مزایا | معایب |
|---|---|---|---|
| واکنشی (Reactive) | بعد از خرابی | ساده، بدون هزینه اولیه | توقف تولید، هزینه بالا، خطر ایمنی |
| برنامهریزیشده (Preventive) | دورهای (مثلاً هر ۳ ماه) | کنترلشده، ساده | احتمال تعمیر زودتر از نیاز، هزینه بالای سرویس غیرضروری |
| پیشگویانه (PdM) | دقیقاً قبل از خرابی | بهینه، اقتصادی، قابل اطمینان | نیاز به سنسور، تحلیل داده، AI |
🔁 فرآیند گامبهگام اجرای نگهداری پیشگویانه
۱. دریافت دادهها
با استفاده از سنسورها: دما، لرزش، فشار، صدا، جریان، توان، روغن و…
ثبت داده به صورت بلادرنگ (Real-Time) یا با فواصل منظم
۲. پیشپردازش دادهها
حذف نویز، نرمالسازی، حذف دادههای ناقص
استخراج ویژگیها (Feature Extraction) مثل: میانگین، RMS، انحراف معیار، انرژی، طیف فرکانسی و…
۳. تحلیل و مدلسازی
تحلیل آماری اولیه
ساخت مدل با الگوریتمهای یادگیری ماشین یا یادگیری عمیق برای:
تشخیص ناهنجاریها (Anomaly Detection)
پیشبینی زمان باقیمانده تا خرابی (RUL)
دستهبندی وضعیت تجهیز (سالم، مستهلک، بحرانی)
4. تصمیمگیری و هشدار
اعلام هشدار زمانی که احتمال خرابی بالا رفت
محاسبه Remaining Useful Life (RUL)
نمایش در داشبورد برای اپراتورها
🧠 الگوریتمهای پرکاربرد در PdM
| نوع الگوریتم | مثال | کاربرد |
|---|---|---|
| یادگیری نظارتشده | Random Forest, SVM, XGBoost | پیشبینی خرابی / طبقهبندی وضعیت |
| یادگیری بدون نظارت | K-Means, DBSCAN, Autoencoder | تشخیص ناهنجاری بدون داده برچسبدار |
| یادگیری عمیق | LSTM, CNN, RNN, GRU | مدلسازی دادههای سریزمانی پیچیده |
| تحلیل فرکانسی | FFT, STFT, Wavelet | تشخیص خطای مکانیکی با لرزش |
| تحلیل پیشبینی RUL | Survival Analysis, Regression, LSTM | برآورد زمان باقیمانده تا خرابی |
🛢️ مثال کاربردی در صنعت نفت و حفاری
مثال: پمپ گل حفاری در دکل نفتی
دادهها: لرزش، دما، جریان برق، زمان کارکرد
مدل: LSTM برای مدلسازی رفتار طبیعی و تشخیص تغییرات
خروجی: هشدار پیش از بروز شکست در یاتاقان پمپ
نتیجه: جلوگیری از توقف ۴۸ ساعته دکل حفاری و صرفهجویی میلیاردی
🧰 ابزارها و تکنولوژیهای رایج
| حوزه | ابزار |
|---|---|
| سنسورها | IEPE Accelerometer, Temp Sensor, Flow Meter |
| جمعآوری داده | PLC, Edge Device, MQTT, OPC UA |
| تحلیل داده | Python (pandas, scikit-learn, keras), MATLAB |
| نمایش داده | Grafana, Power BI, custom dashboards |
| بستر اجرا | Edge computing, Cloud (AWS, Azure, ابر آروان) |
📈 شاخصهای کلیدی عملکرد (KPIs) برای PdM
| KPI | توضیح |
|---|---|
| MTBF (میانگین زمان بین دو خرابی) | بالاتر بهتر |
| MTTR (میانگین زمان تعمیر) | پایینتر بهتر |
| Uptime | درصد زمان کارکرد تجهیزات |
| کاهش هزینه نگهداری | بر اساس مقایسه قبل/بعد PdM |
| RUL Accuracy | دقت پیشبینی زمان باقیمانده تا خرابی |
⚠️ چالشهای PdM در عمل
| چالش | راهحل |
|---|---|
| داده ناکافی از خرابیها | استفاده از روشهای بدون نظارت یا شبیهسازی داده |
| نویز یا ناپایداری در سنسورها | فیلترینگ و اعتبارسنجی داده |
| تنوع در نوع تجهیزات و شرایط کاری | طراحی مدل اختصاصی یا تطبیقی |
| عدم اعتماد اپراتورها | آموزش، بصریسازی، تست پایلوت موفق |
✅ جمعبندی
نگهداری پیشگویانه ترکیبی از علم داده، هوش مصنوعی و دانش فنی صنعتی است.
این رویکرد با تحلیل دادههای واقعی از تجهیزات، میتواند خرابیها را قبل از وقوع شناسایی کرده و منجر به:
کاهش هزینه،
افزایش بهرهوری،
افزایش ایمنی،
و پایداری تولید شود.

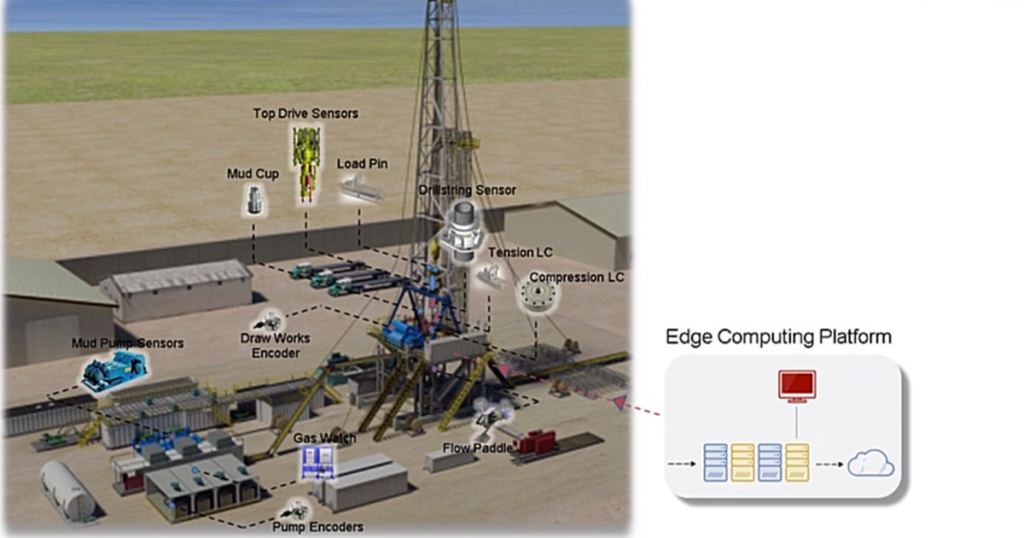
☁️ ۶. معماری سیستم پیشنهادی برای دکلهای حفاری(Predictive Maintenance for Oil Drilling Rigs)
جمعآوری داده از حسگرها
ارسال به کلود (مثلاً Azure یا ابر آروان)
تحلیل در Edge یا Cloud؟
داشبورد مانیتورینگ و هشدارها
امنیت داده و زمان پاسخ
🎯 هدف از طراحی این معماری
پایش بلادرنگ تجهیزات حساس (مثل پمپ گل، تاپدرایو، موتورهای AC/DC، سیستم تدوین گل و …)
پیشبینی زمان خرابیها با دقت بالا
کاهش توقفهای ناگهانی دکل حفاری
افزایش ایمنی پرسنل و بهرهوری عملیات
🧩 اجزای اصلی معماری (5 لایه کلیدی)
+------------------------------+
| 5. لایه تصمیمگیری |
+------------------------------+
| 4. لایه تحلیل و AI |
+------------------------------+
| 3. لایه انتقال داده |
+------------------------------+
| 2. لایه جمعآوری داده |
+------------------------------+
| 1. لایه حسگر و لبه |
+------------------------------+
🔹 ۱. لایه حسگر و لبه (Sensors & Edge Layer)
این لایه اطلاعات خام از تجهیزات را جمع میکند.
سنسورهای پیشنهادی:
| تجهیز | سنسورها |
|---|---|
| پمپ گل | شتابسنج (لرزش), دما، فشار |
| تاپدرایو | شتابسنج، جریان موتور، سرعت |
| موتور اصلی | ولتاژ، جریان، دما، لرزش |
| تجهیزات هیدرولیک | فشار، نویز صوتی، دما |
| سیستم تزریق گل | دبی، ویسکوزیته، سطح مخزن |
تجهیزات لبهای (Edge Devices):
Raspberry Pi Industrial / Jetson Nano / Advantech
قابلیت اجرای مدل ML سبک و فیلتر کردن داده
اتصال به شبکه (LAN/Wi-Fi/4G)
🔹 ۲. لایه جمعآوری داده (Data Acquisition Layer)
وظیفه این لایه: خواندن، پردازش اولیه و ارسال داده به سیستم مرکزی
اجزای کلیدی:
| جزء | وظیفه |
|---|---|
| PLC یا RTU | جمعآوری و زمانبندی داده |
| پروتکلها | Modbus, OPC UA, MQTT |
| دیتالاگر | ذخیره پشتیبان محلی |
| همزمانسازی زمانی | با GPS یا NTP برای دادههای سریزمانی دقیق |
🔹 ۳. لایه انتقال داده (Data Transfer Layer)
انتقال داده از دکل به مرکز داده یا کلود برای تحلیل
روشهای اتصال:
| روش | ویژگی |
|---|---|
| شبکه محلی (LAN) | برای ارتباط داخلی سریع |
| Wi-Fi یا 4G | برای ارسال داده به کلود |
| VSAT یا اینترنت ماهوارهای | در دکلهای دریایی یا مناطق دورافتاده |
| ارسال داده به Cloud یا مرکز تحلیل سازمانی |
ملاحظات امنیتی:
رمزنگاری داده (TLS/SSL)
تأیید هویت دستگاهها
فایروال صنعتی
🔹 ۴. لایه تحلیل و هوش مصنوعی (AI & Analytics Layer)
قلب اصلی پیشبینی خرابی در این لایه است.
وظایف:
پیشپردازش (تمیز کردن نویز، نرمالسازی)
استخراج ویژگیها از سیگنالها (فرکانسی، آماری، صوتی و…)
تحلیل الگوها (با استفاده از الگوریتمهای ML/DL)
پیشبینی Remaining Useful Life (RUL)
تشخیص ناهنجاری (Anomaly Detection)
تکنولوژیها و زبانها:
| ابزار | کاربرد |
|---|---|
| Python (Scikit-learn, Tensorflow, PyTorch) | مدلهای یادگیری ماشین و LSTM |
| Edge ML (Tensorflow Lite, ONNX) | اجرای مدل روی دستگاههای لبهای |
| MATLAB | تحلیل سیگنال و پروتوتایپ مدلها |
| Azure/AWS/ابر آروان | کلود و مانیتورینگ بلادرنگ |
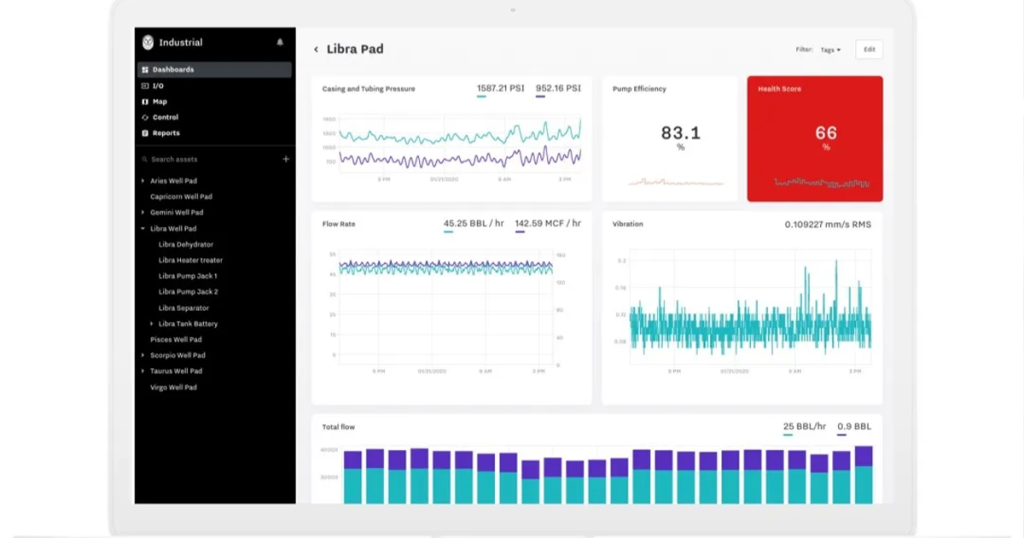
🔹 ۵. لایه تصمیمگیری و داشبورد (Decision & Visualization Layer)
این لایه خروجیها را برای کاربر نهایی قابلفهم میکند.
قابلیتها:
نمایش وضعیت لحظهای هر تجهیز
هشدارها و اعلانها (SMS/ایمیل/اپلیکیشن)
نمودارهای روند سلامت تجهیزات
پیشبینی زمان باقیمانده تا خرابی (RUL)
توصیههای تعمیر یا سرویسکاری
ابزارها:
| ابزار | ویژگی |
|---|---|
| Grafana | نمودارهای بلادرنگ |
| Power BI | تحلیل دورهای |
| اپلیکیشن موبایل | هشدارهای فوری |
| داشبورد سفارشی تحت وب | مخصوص دکل حفاری |
🔄 جریان داده از سنسور تا تصمیم
[Sensor]
↓
[PLC / Edge Device] (پیشپردازش اولیه)
↓
[MQTT / OPC UA]
↓
[Cloud / Server AI Model] (پیشبینی RUL یا تشخیص ناهنجاری)
↓
[Dashboard / Alert System] (تصمیمگیری و اقدام انسانی)
🛑 ملاحظات ویژه برای دکلهای حفاری
| نکته | توضیح |
|---|---|
| شرایط محیطی سخت | نیاز به سنسور مقاوم به لرزش، گردوغبار، دما |
| اتصال محدود به اینترنت | استفاده از Edge AI + ارسال خلاصه دیتا |
| اهمیت ایمنی | اولویت با سیستم هشدار سریع و دقیق |
| هماهنگی با SCADA موجود | قابلیت یکپارچهسازی با سیستم حفاری موجود |
✅ خروجی نهایی برای سازمان
| خروجی | مزیت |
|---|---|
| کاهش توقفهای ناگهانی | صرفهجویی میلیاردی |
| پیشبینی دقیق زمان خرابی | برنامهریزی دقیق سرویس |
| افزایش عمر مفید تجهیزات | کاهش هزینه سرمایهای |
| افزایش ایمنی کارکنان | کاهش حوادث در دکل |
📚 منابع پیشنهادی برای مطالعه سریع:
کتابهای خلاصهوار مثل:
“Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow”
دورههای فشرده Coursera یا YouTube در موضوعات زیر:
Time Series Forecasting
Predictive Maintenance using ML
مطالعه مقالات صنعتی در سایتهایی مثل:






{kind=link}
بدون دیدگاه